My Experience with Amazon SageMaker and Integrating with a Rails App
I recently tried Amazon SageMaker, a more hands on version Amazon Machine Learning. I am pretty new to machine learning, but I found it pretty easy to use. SageMaker is a little unpolished/buggy at this time so I will be listing all the problems I encountered and how I solved them.
1) EnvironmentLocationNotFound: Not a conda environment: /home/ec2-user/anaconda3/envs/anaconda3
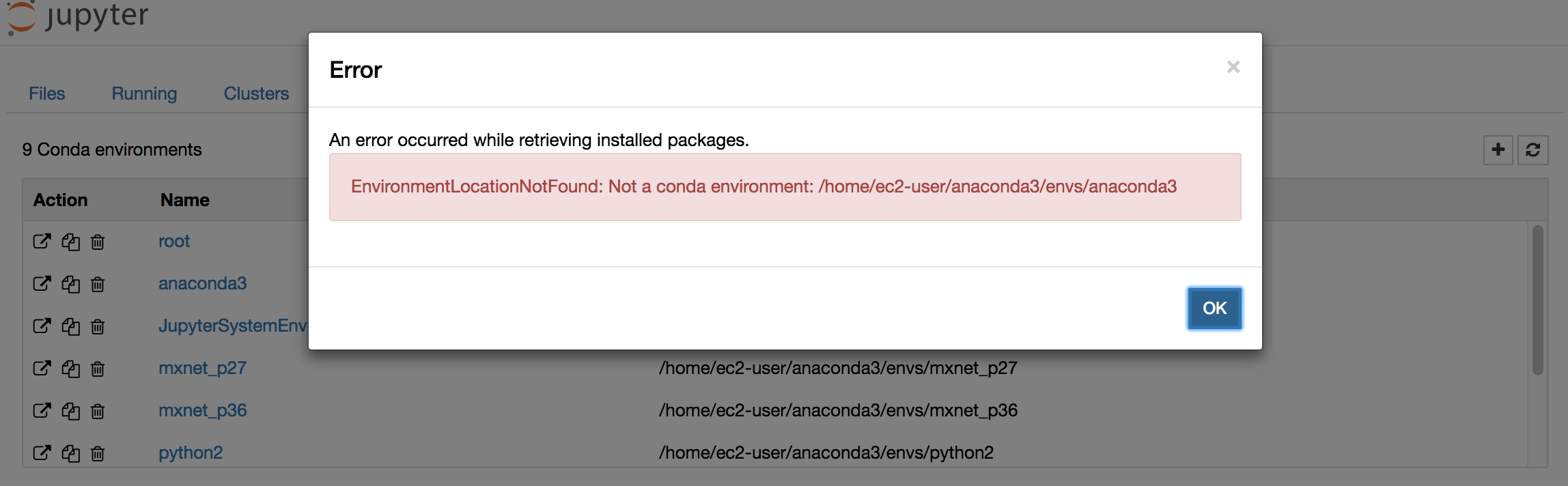
Not sure why this pops up or what it is, but I saw it pop up even in Amazon’s demo video. But this didn’t hinder what I was trying to do.
2) Installing new packages in a Conda environment
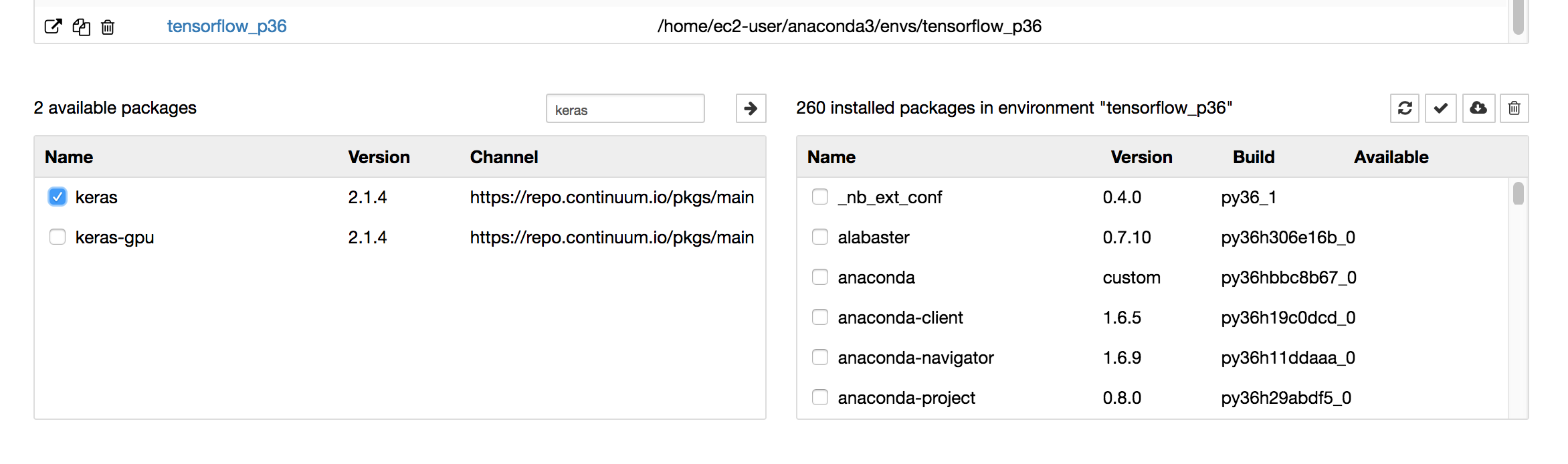
The UI of of the Jupyter notebook isn’t that intuitive, but in order to install Keras, I selected tensorflow_p36 and it showed me what were the installed packages on the right side. The left bottom side is what other packages can be installed. Pressing the arrow on the top left corner, installs the selected package(s) to that environment.
3) Lack of AWS Ruby SDK Documentation
The gem version I am using is 2.11.14. There is a version 3, but the rest of the codebase has not been migrated yet so I stuck with version 2. The SageMaker documentation is here for v2: link , but there’s no example of how to use their methods (ex: invoke_endpoint). I am going to include my simple script to use an endpoint on SageMaker for a model (ex: Linear Learner) I created
sage_maker = Aws::SageMakerRuntime::Client.new(
region: '[AWS_REGION]',
access_key_id: '[ACCESS_KEY_ID]',
secret_access_key: '[SECRET_ACCESS_KEY]'
)
data = "2,0,5,0.111146,350,0.159476,531.064,2799,3149,0.111146,350,51.0407,40.3026,0.111146,350,0.0217391,256.684,0.0715644,350,0.111146,787.747,0.219627\n"
data += "0,0,2,0.3,12.3,0.176471,6.15,28.7,41,0.3,12.3,2.60878,1.30439,0.176471,6.15,0.0217391,6.15,0.15,12.3,0.3,12.3,0.3\n"
resp =sage_maker.invoke_endpoint({
endpoint_name: "[ENDPOINT_NAME]]",
body: data,
content_type: "text/csv",
accept: "text/html",
})
p resp.body.string
# => "0.49,0.5" for xgboost
# => "{\"predictions\": [{\"score\": 0.7134652733802795, \"predicted_label\": 1.0}, {\"score\": 0.7784065008163452, \"predicted_label\": 1.0}]}" for linear learner Data is all the parameters (in the same order as training the model) to make a prediction on, you can send as many records as you want. I tried over 100 records/lines and it was able to return results for every single one of them in one request. I included sample return strings for Linear Learner model and XGBoost model. It turns out sdk returns different strings from different models.
If there is an error with the call, the sdk actually gives a link to CloudWatch to help debugging.
Final Words
I was able to borrow example tutorials like using the XGBoost model link and easily modify it to produce a model, store it on S3 and create an endpoint for the Rails app to use. It was pretty easy to use overall.